


Hello everyone,
In this article we will discuss what role does Confusion Matrix plays in the Cybersecurity field??
As we all know that cybersecurity is very important as they are responsible for our security from cybercrime and the tools and tech they use are very important for them and what if I say that the tool that they use can give them wrong information !! If this happens that worst-case scenario may occur.
so before we start with that topic let's discuss what confusion matrix is and what is cybersecurity?
What is Cyber Security?
Cybersecurity is the practice of protecting systems, networks, and programs from digital attacks, here digital attacks can be stealing information or spying on another system, and much more. There are cybersecurity experts present whose work is to protect users or prevent the digital attack, here digital attack is also known as cybercrime.
Cyber Crimes are increasing day by day, here is some example of cybercrime that took place in 2021 and this will give you the idea that how important is cybersecurity :
- Australian broadcaster Channel Nine was hit by a cyberattack on 28th March 2021, which rendered the channel unable to air its Sunday news bulletin and several other shows.
- In March 2021, the London-based Harris Federation suffered a ransomware attack and was forced to “temporarily” disable the devices and email systems of all the 50 secondary and primary academies it manages. This resulted in over 37,000 students being unable to access their coursework and correspondence.
- A cybercriminal attempted to poison the water supply in Florida and managed by increasing the amount of sodium hydroxide to a potentially dangerous level.
- Acer suffered a ransomware attack and was asked to pay a ransom of $50 million, which made the record of the largest known ransom to date
By going through the cyber crimes that happened in 2021, we can understand that how important is cybersecurity.
What is Confusion Matrix?
Confusion Matrix is a concept that is used to find the accuracy of the model that we create in Machine learning or we can explain it as a table that is often used to describe the performance of a classification model on a set of test data for which the true values are known.
The basic terms that the Confusion matrix has are:
- True Positive [ TP ]: In TP, the Machine Learning model predicted right and it was actually right.
- True Negative [ TN ]: In TN, the Machine Learning model predicted right but actually it was the wrong prediction, also called False alarm.
- False Positive [ FP ]: In FP, the model predicts the wrong but actually it was right
- False Negative [FN ]: In FN, the model predicted wrong and actually it as wrong.
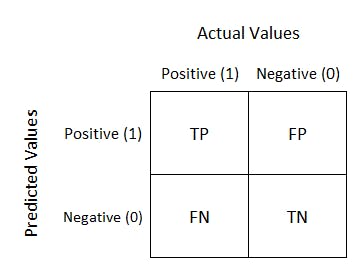
There are two types of error in the confusion matrix:
- False Negative and
- False Positive
The most dangerous error is the False Positive [FP] error as the machine predicted false but it was not false it was true. For example, the machine predicted student fails but actually student was a pass.
This error causes problems in the cybersecurity world where the tools used are based on machine learning or ai, it may give a False Negative error that may cause dangerous impacts.
Therefore the role of the confusion matrix is important in the field of machine learning.
Cyber Attack Detection and Classification using Parallel Support Vector Machine
Support Vector Machines (SVM) are the classifiers that were originally designed for binary c1assification. The c1assificatioin applications can solve multi-class problems. The result shows that pSVM gives more detection accuracy for classes and comparable to the false alarm rate.
Cyberattack detection is a classification problem, in which we classify the normal pattern from the abnormal pattern (attack) of the system.
The SDF is a very powerful and popular data mining algorithm for decision-making and classification problems. It has been using in many real-life applications like medical diagnosis, radar signal classification, weather prediction, credit approval, and fraud detection, etc.
A parallel Support Vector Machine (pSVM) algorithm was proposed for the detection and classification of cyber attack datasets.
The performance of the support vector machine is greatly dependent on the kernel function used by SVM. Therefore, we modified the Gaussian kernel function in a data-dependent way in order to improve the efficiency of the classifiers. The relative results of both the classifiers are also obtained to ascertain the theoretical aspects. The analysis is also taken up to show that PSVM performs better than SDF.
The classification accuracy of PSVM remarkably improve (accuracy for Normal class as well as DOS class is almost 100%) and comparable to false alarm rate and training, testing times.
KDD CUP ‘’99 Data Set Description
This data set is prepared by Stolfo et al and is built based on the data captured in the DARPA’98 IDS evaluation program . DARPA’98 is about 4 gigabytes of compressed raw (binary) TCP dump data of 7 weeks of network traffic, which can be processed into about 5 million connection records, each with about 100 bytes.
For each TCP/IP connection, 41 various quantitative (continuous data type) and qualitative (discrete data type) features were extracted among the 41 features, 34 features (numeric), and 7 features (symbolic).
To analysis the different results, there are standard metrics that have been developed for evaluating network intrusion detections. Detection Rate (DR) and false alarm rate are the two most famous metrics that have already been used. DR is computed as the ratio between the number of correctly detected attacks and the total number of attacks, while the false alarm (false positive) rate is computed as the ratio between the number of normal connections that is incorrectly misclassified as attacks and the total number of normal connections.

In parallel SVM machine first we reduced nonclassified features data by distance matrix of binary pattern. From this concept, the cascade structure is developed by initializing the problem with a number of independent smaller optimizations and the partial results are combined in later stages in a hierarchical way, as shown in figure 1, supposing the training data subsets and are independent among each other.
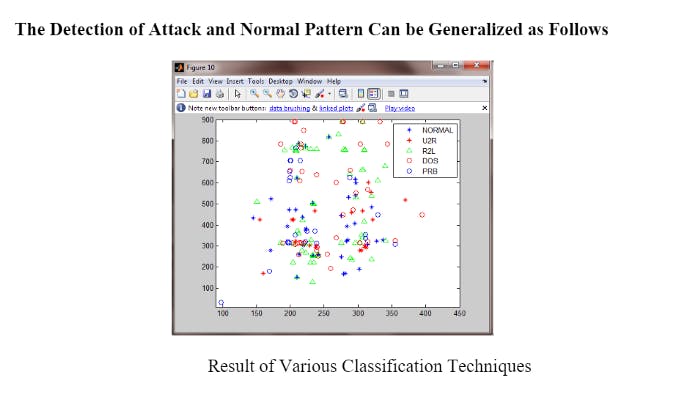
- True Positive (TP): The amount of attack detected when it is actually attack.
- True Negative (TN): The amount of normal detected when it is actually normal.
- False Positive (FP): The amount of attack detected when it is actually normal (False alarm).
- False Negative (FN): The amount of normal detected when it is actually attack.
