


Introduction
K-Means Clustering is an Unsupervised Learning algorithm, which groups the unlabeled dataset into different clusters.
let's break down this statement into sub terminologies to understand better what K-mean clustering means.
- What is Unsupervised Learning?
Unsupervised Learning is a machine learning technique in which, there are no labels for the training data. A machine learning algorithm tries to learn the underlying patterns or distributions that govern the data.
- What is Clustering?
A cluster refers to a collection of data points aggregated together because of certain similarities.
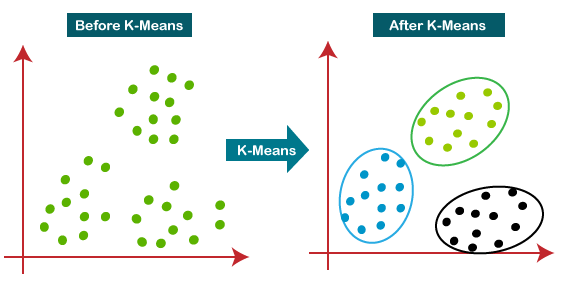
- What is K-means?
K-means is an algorithm that identifies k number of centroids and then allocates every data point to the nearest cluster while keeping the centroids as small as possible.
Here "K" refers to the number of centroids we need in the dataset. A centroid is the imaginary or real location representing the center of the cluster.
- What does "means" refer to in K-means?
The ‘means’ in the K-means refers to averaging of the data, that is finding the centroid.
K-mean Clustering Usecase in Security:
- Cyber profiling criminal
Cyber profiling is the process of collecting data from individuals and groups to identify significant co-relations. the idea of cyber profiling is derived from criminal profiles, which provide information on the investigation division to classify the types of criminals who were at the crime scene. here is an interesting white paper on how to cyber-profile users in an academic environment based on user data preferences.
Through K-mean Clustering algorithms, the data can be grouped by the number of websites visited. This grouping aims to see what the user frequently accesses websites.
The data of internet users access at an institution can be categorized as a large data type so that the analysis can be done with data mining. In this case, the cluster algorithm as one of data mining techniques can be used to find groups (clusters) of a useful object, which the used are depends on the purpose of data analysis.
Clustering analysis is one of the most useful methods for the acquisition of knowledge and is used to find clusters that are a fundamental and important pattern for the distribution of the data itself
- Insurance fraud detection
Machine learning has a critical role to play in fraud detection and has numerous applications in automobile, healthcare, and insurance fraud detection. utilizing past historical data on fraudulent claims, it is possible to isolate new claims based on its proximity to clusters that indicate fraudulent patterns. since insurance fraud can potentially have a multi-million dollar impact on a company, the ability to detect frauds is crucial.